Introduction to GPU tracking
AdePT is designed as a Geant4 plugin that accelerates applications by offloading tracking to the GPU. To minimize changes in existing applications, AdePT invokes user code almost exactly as Geant4 does.
At the same time, GPU transport is inherently parallel, while Geant4 CPU tracking is inherently serial. This difference cannot be eliminated and has practical consequences for user actions and sensitive detectors.
This page explains the offloading model, the resulting behavior changes, and best practices for integrating user code.
Offloading of tracks to the GPU
Like G4HepEm, AdePT uses the virtual Geant4
G4VTrackingManager class
to provide custom tracking for selected particle types.
This custom tracking is implemented in AdePTTrackingManager, an implementation of the virtual G4VTrackingManager. Once a
G4VTrackingManager implementation is attached to a particle type, Geant4
delegates tracking of that particle type entirely to the custom manager.
Currently, AdePTTrackingManager is attached to electrons, positrons, and
gammas.
The flow graph is shown in Figure 1:
Geant4 pops a particle from the stack.
If it is an electron, positron, or gamma, the track is handed to
AdePTTrackingManager; otherwise, it remains in standard Geant4 tracking.Inside
AdePTTrackingManager, the track is passed either to CPU or GPU.CPU path: hand over to
G4HepEmTrackingManagerfor efficient CPU tracking. TheG4HepEmTrackingManageris itself an implementation of theG4VTrackingManagerthat provides an optimized transport of electrons, positrons, and gammas on CPU.GPU path: offload to AdePT GPU transport.
AdePT supports G4Region-based routing. You can run tracks on GPU in:
all regions,
all except selected regions, or
only selected regions.
Regions can be kept on CPU. For example, if a detector uses a parameterized shower and tracks only few particles in that region, it can be faster to keep that detector part on CPU, since that parameterized shower is not implemented on GPU yet.
The runtime controls for region-based offloading are documented in Specify the regions where the GPU is used.
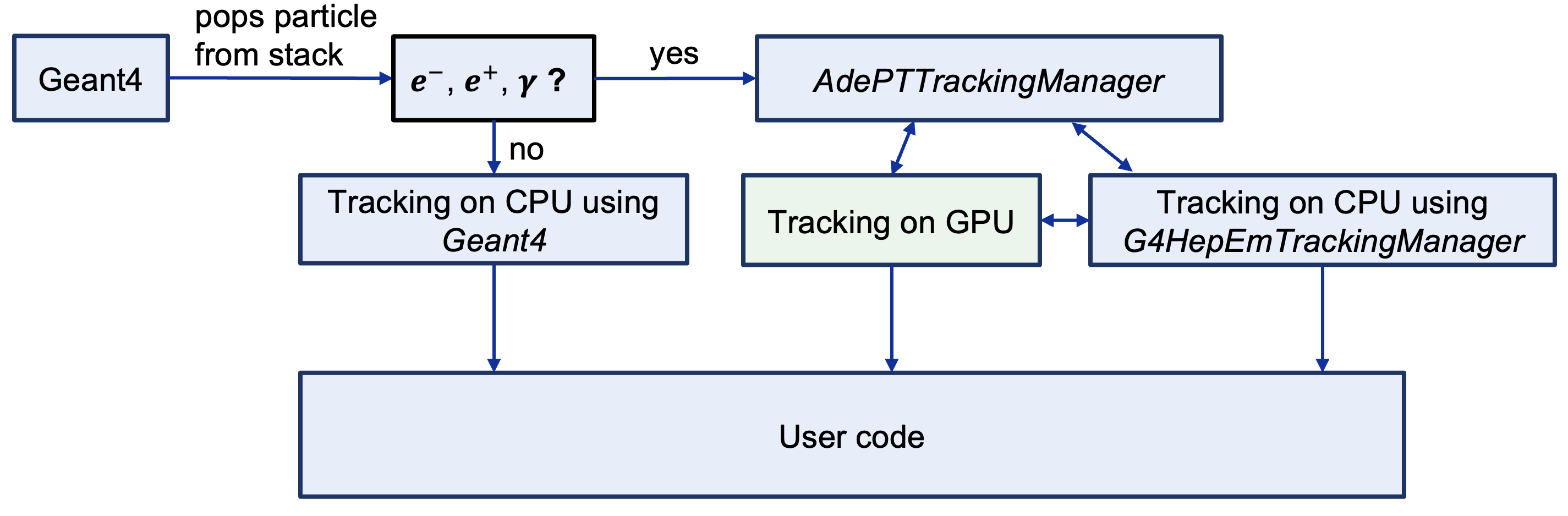
Figure 1 Offloading of electron, positron, and gamma tracks from Geant4 CPU tracking to AdePT GPU transport.
To avoid application-side code changes, AdePT aims to keep user-code callbacks
consistent with Geant4 behavior (sensitive detectors, TrackingAction,
SteppingAction, etc.). To do this, step information is copied back from GPU to
CPU before invoking user code. The implications are described in
User code in GPU-enabled simulations.
User code in GPU-enabled simulations
AdePT does not require user code to be ported to GPU: GPU step information is copied back to CPU, and CPU user code is invoked there.
However, because GPU tracking is parallel, this model introduces stricter rules.
Serial tracking in Geant4
In Geant4, tracks are processed serially, as shown in Figure 2.
The gray parent track is processed first:
PreUserTrackingAction(TA) is called.The track advances step by step;
SteppingAction(SA) is called at each step (including bothG4UserSteppingActionand sensitive-detector calls).If secondaries are produced, they are pushed onto the stack.
At end of track,
PostUserTrackingActionandStackingAction(SkA) are called.SkA loops over secondaries and classifies which tracks to process next.
Figure 2 Sketch of the serial tracking sequence in Geant4.
Parallel tracking in AdePT
In AdePT, tracks are processed in parallel, as shown in Figure 3.
As soon as the gray parent track produces a secondary, that secondary is tracked immediately in the next step. In realistic jobs, many tracks can be active in parallel.
Because of that, a Geant4-style SkA stage is not suitable on GPU: the GPU should not wait for track end before deciding on secondaries. Instead, decisions must be made immediately in stepping logic on GPU.
Figure 3 Sketch of the parallel tracking sequence in AdePT.
Consequences for CPU user code
To invoke the same user actions on CPU, AdePT copies GPU step information back to CPU. Since tracks are processed in parallel, steps can return interleaved across tracks. This has two key consequences:
The CPU no longer receives active
G4Trackobjects, but reconstructed steps from GPU. These reflect the outcome of the step, and the real track may already have advanced or finished on GPU. Consequently, the track cannot be killed inUserSteppingActionor in a sensitive detector, because that would only affect the copied step on CPU, not the real track on GPU.Steps arrive in order per track, but interleaved with steps from other tracks. Therefore, user actions must not cache per-track state in shared members (for example,
m_initial_fourmomentum), because such state becomes invalid when tracks are interleaved. This information must be stored with the track itself, e.g. inG4VUserTrackInformation.
Summary of do’s and don’ts
Topic |
Do |
Don’t |
Why |
|---|---|---|---|
Access to tracking state |
Use |
Do not rely on |
With custom tracking and parallel execution, manager internals are not reliable integration points, as they are not used by the |
Per-track state in user code |
Store per-track state on the track (e.g. |
Do not cache mutable per-track state in shared user-action or SD members. |
Steps from different tracks can be interleaved, so caches can be invalidated. |
Track killing |
Implement track-killing decisions on GPU. |
Do not attempt to kill tracks from CPU stepping action or sensitive detector code. |
CPU receives reconstructed step snapshots, not active GPU tracks. |
Classification logic |
Implement immediate classification in GPU stepping logic. |
Do not rely on |
GPU transport processes secondaries immediately; there is no GPU |
Note: G4Trajectory is currently stored in G4TrackingManager, so it is not
parallel-tracking compatible in this workflow. This requires a Geant4-side fix.